Коллекции
___
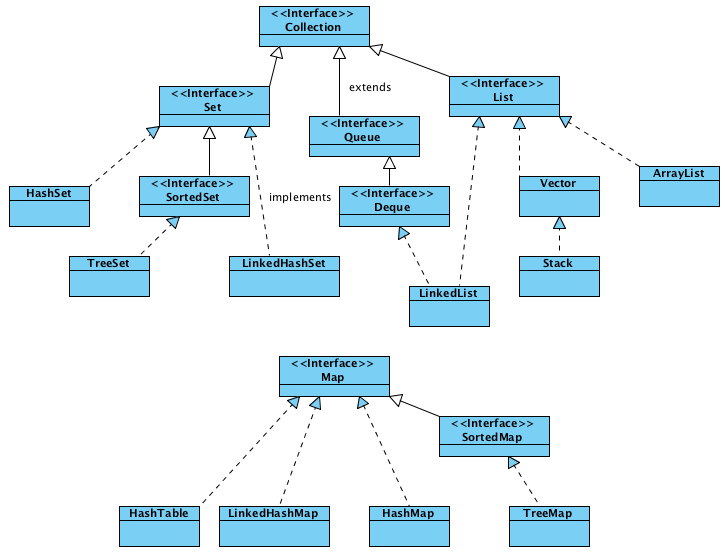
В библиотеке коллекций Java(Java Collections Framework) существует два базовых интерфейса, реализации которых и представляют совокупность всех классов коллекций:
Collection - коллекция содержит набор объектов (элементов). Здесь определены основные методы для манипуляции с данными, такие как вставка (add, addAll), удаление (remove, removeAll, clear), поиск (contains)
Map - описывает коллекцию, состоящую из пар "ключ — значение". У каждого ключа только одно значение, что соответствует математическому понятию однозначной функции или отображения (тар). Такую коллекцию часто называют еще словарем (dictionary) или ассоциативным массивом (associative array). Никак НЕ относится к интерфейсу Collection и является самостоятельным.
___
Все коллекции в Java реализуют интерфейс Iterable.
___
___
На этом изображении также недостает интерфейсов NavigableSet и NavigableMap, находящихся между SortedSet/SortedMap и TreeSet/TreeMap, а также класса PriorityQueue.
___
Interface List
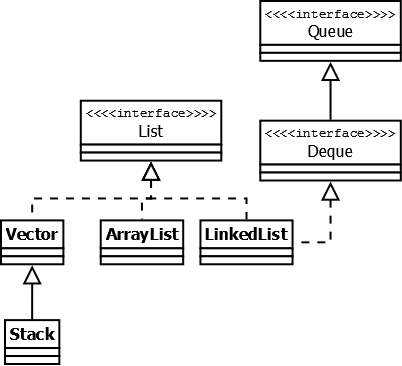
Реализации этого интерфейса представляют собой упорядоченные коллекции. Кроме того, разработчику предоставляется возможность доступа к элементам коллекции по индексу и по значению (так как реализации позволяют хранить дубликаты, результатом поиска по значению будет первое найденное вхождение).
Vector — реализация динамического массива объектов. Позволяет хранить любые данные, включая null в качестве элемента. Как и Hashtable, эту коллекцию не рекомендуется использовать, если не требуется достижения потокобезопасности. Потому как в Vector, в отличии от других реализаций List, все операции с данными являются синхронизированными.
Stack — данная коллекция является расширением коллекции Vector. Была добавлена в Java 1.0 как реализация стека LIFO (last-in-first-out). Является частично синхронизированной коллекцией (кроме метода добавления push()). После добавления в Java 1.6 интерфейса Deque, рекомендуется использовать именно реализации этого интерфейса, например ArrayDeque.
ArrayList — как и Vector является реализацией динамического массива объектов. Позволяет хранить любые данные, включая null в качестве элемента. Как можно догадаться из названия, его реализация основана на обычном массиве. Данную реализацию следует применять, если в процессе работы с коллекцией предплагается частое обращение к элементам по индексу. Из-за особенностей реализации поиндексное обращение к элементам выполняется за константное время O(1). Но данную коллекцию рекомендуется избегать, если требуется частое удаление/добавление элементов в середину коллекции.
LinkedList — ещё одна реализация List. Позволяет хранить любые данные, включая null. Особенностью реализации данной коллекции является то, что в её основе лежит двунаправленный связный список (каждый элемент имеет ссылку на предыдущий и следующий). Благодаря этому, добавление и удаление из середины, доступ по индексу, значению происходит за линейное время O(n), а из начала и конца за константное O(1). Так же, ввиду реализации, данную коллекцию можно использовать как стек или очередь.
___
Interface Set
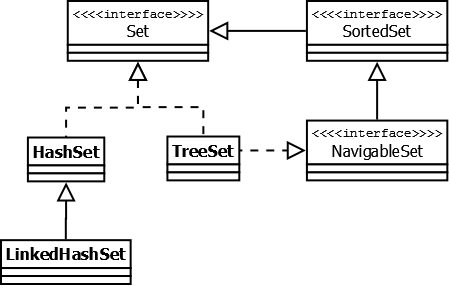
Представляет собой неупорядоченную коллекцию, которая не может содержать дублирующиеся данные. Является программной моделью математического понятия «множество».
HashSet — реализация интерфейса Set, базирующаяся на HashMap. Внутри использует объект HashMap для хранения данных. В качестве ключа используется добавляемый элемент, а в качестве значения — объект-пустышка (new Object()). Из-за особенностей реализации порядок элементов не гарантируется при добавлении.
LinkedHashSet — отличается от HashSet только тем, что в основе лежит LinkedHashMap вместо HashSet. Благодаря этому отличию порядок элементов при обходе коллекции является идентичным порядку добавления элементов.
TreeSet — аналогично другим классам-реализациям интерфейса Set содержит в себе объект NavigableMap, что и обуславливает его поведение. Предоставляет возможность управлять порядком элементов в коллекции при помощи объекта Comparator, либо сохраняет элементы с использованием "natural ordering".
___
Interface Queue

Этот интерфейс описывает коллекции с предопределённым способом вставки и извлечения элементов, а именно — очереди FIFO (first-in-first-out). Помимо методов, определённых в интерфейсе Collection, определяет дополнительные методы для извлечения и добавления элементов в очередь. Большинство реализаций данного интерфейса находится в пакете java.util.concurrent и подробно рассматриваются в данном обзоре.
PriorityQueue — является единственной прямой реализацией интерфейса Queue (была добавлена, как и интерфейс Queue, в Java 1.5), не считая класса LinkedList, который так же реализует этот интерфейс, но был реализован намного раньше. Особенностью данной очереди является возможность управления порядком элементов. По-умолчанию, элементы сортируются с использованием «natural ordering», но это поведение может быть переопределено при помощи объекта Comparator, который задаётся при создании очереди. Данная коллекция не поддерживает null в качестве элементов.
ArrayDeque — реализация интерфейса Deque, который расширяет интерфейс Queue методами, позволяющими реализовать конструкцию вида LIFO (last-in-first-out). Эта коллекция представляет собой реализацию с использованием массивов, подобно ArrayList, но не позволяет обращаться к элементам по индексу и хранение null. Как заявлено в документации, коллекция работает быстрее чем Stack, если используется как LIFO коллекция, а также быстрее чем LinkedList, если используется как FIFO.
___
Interface Map

Hashtable — реализация такой структуры данных, как хэш-таблица. Она не позволяет использовать null в качестве значения или ключа. Как и другие коллекции из Java 1.0, Hashtable является синхронизированной (почти все методы помечены как synchronized). Из-за этой особенности у неё имеются существенные проблемы с производительностью и в большинстве случаев рекомендуется использовать другие реализации интерфейса Map ввиду отсутствия у них синхронизации.
HashMap — коллекция является альтернативой Hashtable.
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null(в отличии от HashTable). Для хранения примитивных типов используются соответствующие классы-оберки;
— Данная коллекция не является упорядоченной: порядок хранения элементов зависит от хэш-функции;
— Разрешение коллизий ведется с помощью метода цепочек;
— Не синхронизирован(в отличии от HashTable).
LinkedHashMap — это упорядоченная реализация хэш-таблицы. Здесь, в отличии от HashMap, порядок итерирования равен порядку добавления элементов. Данная особенность достигается благодаря двунаправленным связям между элементами (аналогично LinkedList). Но это преимущество имеет также и недостаток — увеличение памяти, которое занимет коллекция. Структура может слегка уступать по производительности родительскому HashMap, при этом время выполнения операций add(), contains(), remove() остается константой — O(1). Понадобится чуть больше места в памяти для хранения элементов и их связей, но это совсем небольшая плата за дополнительные фишечки.
TreeMap — реализация Map основанная на красно-чёрных деревьях. Как и LinkedHashMap является упорядоченной. По-умолчанию, коллекция сортируется по ключам с использованием принципа "natural ordering", но это поведение может быть настроено под конкретную задачу при помощи объекта Comparator, которые указывается в качестве параметра при создании объекта TreeMap.
WeakHashMap — реализация хэш-таблицы, которая организована с использованием weak references. Другими словами, Garbage Collector автоматически удалит элемент из коллекции при следующей сборке мусора, если на ключ этого элеметна нет жёстких ссылок.
___
Сравнение коллекций
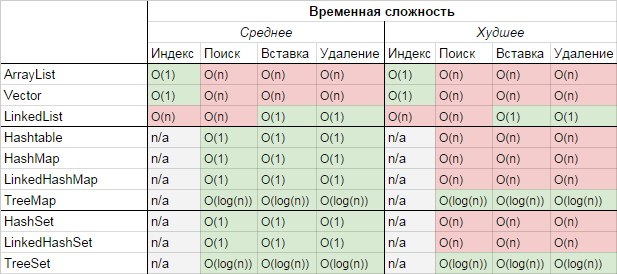
___
Разбор java.util.Concurrent
1. Concurrent Collections
CopyOnWrite коллекции
Название говорит само за себя. Все операции по изменению коллекции (add, set, remove) приводят к созданию новой копии внутреннего массива. Тем самым гарантируется, что при проходе итератором по коллекции не кинется ConcurrentModificationException. Следует помнить, что при копировании массива копируются только референсы (ссылки) на объекты (shallow copy), т.ч. доступ к полям элементов не thread-safe. CopyOnWrite коллекции удобно использовать, когда write операции довольно редки, например при реализации механизма подписки listeners и прохода по ним.
- CopyOnWriteArrayList<E> — Потокобезопасный аналог ArrayList, реализованный с CopyOnWrite алгоритмом.
- CopyOnWriteArraySet<E> — Имплементация интерфейса Set, использующая за основу CopyOnWriteArrayList. В отличии от CopyOnWriteArrayList, дополнительных методов нет.
Scalable Maps
Улучшенные реализации HashMap, TreeMap с лучшей поддержкой многопоточности и масштабируемости.
- ConcurrentMap<K, V> — Интерфейс, расширяющий Map несколькими дополнительными атомарными операциями.
- ConcurrentHashMap<K, V> — В отличие от Hashtable и блоков synhronized на HashMap, данные представлены в виде сегментов, разбитых по hash'ам ключей. В результате, для доступ к данным лочится по сегментам, а не по одному объекту. В дополнение, итераторы представляют данные на определенный срез времени и не кидают ConcurrentModificationException.
- ConcurrentNavigableMap<K,V> — Расширяет интерфейс NavigableMap и вынуждает использовать ConcurrentNavigableMap объекты в качестве возвращаемых значений. Все итераторы декларируются как безопасные к использованию и не кидают ConcurrentModificationException.
- ConcurrentSkipListMap<K, V> — Является аналогом TreeMap с поддержкой многопоточности. Данные также сортируются по ключу и гарантируется усредненная производительность log(N) для containsKey, get, put, remove и других похожих операций. Алгоритм работы SkipList описан на Wiki и хабре.
- ConcurrentSkipListSet<E> — Имплементация Set интерфейса, выполненная на основе ConcurrentSkipListMap.
2. Queues
Non-Blocking Queues
Потокобезопасные и неблокирующие имплементации Queue на связанных нодах (linked nodes).
- ConcurrentLinkedQueue<E> — В имплементации используется wait-free алгоритм от Michael & Scott, адаптированный для работы с garbage collector'ом. Этот алгоритм довольно эффективен и, что самое важное, очень быстр, т.к. построен на CAS. Метод size() может работать долго, т.ч. лучше постоянно его не дергать. Детальное описание алгоритма можно посмотреть тут тут.
- ConcurrentLinkedDeque<E> — Deque расшифровывается как Double ended queue и читается как «Deck». Это означает, что данные можно добавлять и вытаскивать с обоих сторон. Соответственно, класс поддерживает оба режима работы: FIFO (First In First Out) и LIFO (Last In First Out). На практике, ConcurrentLinkedDeque стоит использовать только, если обязательно нужно LIFO, т.к. за счет двунаправленности нод данный класс проигрывает по производительности на 40% по сравнению с ConcurrentLinkedQueue.
Blocking Queues
- BlockingQueue<E> — При обработке больших потоков данных через очереди становится явно недостаточно использования ConcurrentLinkedQueue. Если потоки, разгребающие очередь перестанут справляться с наплывом данных, то можно довольно быстро схлопотать out of memory или перегрузить IO/Net настолько, что производительность упадет в разы пока не настанет отказ системы по таймаутам или из за отсутствия свободных дескрипторов в системе. Для таких случаев нужна queue с возможностью задать размер очереди или с блокировками по условиям. Тут то и появляется интерфейс BlockingQueue, открывающий дорогу к целому набору полезных классов. Помимо возможности задавать размер queue, добавились новые методы, которые реагируют по-разному на незаполнение или переполнение queue. Так, например, при добавлении элемента в переполненную queue, один метод кинет IllegalStateException, другой вернет false, третий заблокирует поток, пока не появится место, четвертый же заблокирует поток с таймаутом и вернет false, если место так и не появится. Также стоит отметить, что блокирующие очереди не поддерживают null значения, т.к. это значение используется в методе poll как индикатор таймаута.
- ArrayBlockingQueue<E> — Класс блокирующей очереди, построенный на классическом кольцевом буфере. Помимо размера очереди, доступна возможность управлять «честностью» блокировок. Если fair=false (по умолчанию), то очередность работы потоков не гарантируется. Более подробно о «честности» можно посмотреть в описании ReentrantLock'a.
- DelayQueue<E extends Delayed> — Довольно специфичный класс, который позволяет вытаскивать элементы из очереди только по прошествии некоторой задержки, определенной в каждом элементе через метод getDelay интерфейса Delayed.
- LinkedBlockingQueue<E> — Блокирующая очередь на связанных нодах, реализованная на «two lock queue» алгоритме: один лок на добавление, другой на вытаскивание элемента. За счет двух локов, по сравнению с ArrayBlockingQueue, данный класс показывает более высокую производительность, но и расход памяти у него выше. Размер очереди задается через конструктор и по умолчанию равен Integer.MAX_VALUE.
- PriorityBlockingQueue<E> — Является многопоточной оберткой над PriorityQueue. При вставлении элемента в очередь, его порядок определяется в соответствии с логикой Comparator'а или имплементации Comparable интерфейса у элементов. Первым из очереди выходит самый наименьший элемент.
- SynchronousQueue<E> — Эта очередь работает по принципу один вошел, один вышел. Каждая операция вставки блокирует «Producer» поток до тех пор, пока «Consumer» поток не вытащит элемент из очереди и наоборот, «Consumer» будет ждать пока «Producer» не вставит элемент.
- BlockingDeque<E> — Интерфейс, описывающий дополнительные методы для двунаправленной блокирующей очереди. Данные можно вставлять и вытаскивать с двух сторон очереди.
- LinkedBlockingDeque<E> — Двунаправленная блокирующая очередь на связанных нодах, реализованная как простой двунаправленный список с одним локом. Размер очереди задается через конструктор и по умолчанию равен Integer.MAX_VALUE.
- TransferQueue<E> — Данный интерфейс может быть интересен тем, что при добавлении элемента в очередь существует возможность заблокировать вставляющий «Producer» поток до тех пор, пока другой поток «Consumer» не вытащит элемент из очереди. Блокировка может быть как с таймаутом, так и вовсе может быть заменена проверкой на наличие ожидающих «Consumer»ов. Тем самым появляется возможность реализации механизма передачи сообщений с поддержкой как синхронных, так и асинхронных сообщений.
- LinkedTransferQueue<E> — Реализация TransferQueue на основе алгоритма Dual Queues with Slack. Активно использует CAS и парковку потоков, когда они находятся в режиме ожидания.
3. Atomics
- AtomicBoolean, AtomicInteger, AtomicLong, AtomicIntegerArray, AtomicLongArray — Что если в классе нужно синхронизировать доступ к одной простой переменной типа int? Можно использовать конструкции с synchronized, а при использовании атомарных операций set/get, подойдет также и volatile. Но можно поступить еще лучше, использовав новые классы Atomic*. За счет использования CAS, операции с этими классами работают быстрее, чем если синхронизироваться через synchronized/volatile. Плюс существуют методы для атомарного добавления на заданную величину, а также инкремент/декремент.
- AtomicReference — Класс для атомарных операцией с ссылкой на объект.
- AtomicMarkableReference — Класс для атомарных операцией со следующей парой полей: ссылка на объект и битовый флаг (true/false).
- AtomicStampedReference — Класс для атомарных операцией со следующей парой полей: ссылка на объект и int значение.
- AtomicReferenceArray — Массив ссылок на объекты, который может атомарно обновляться.
___